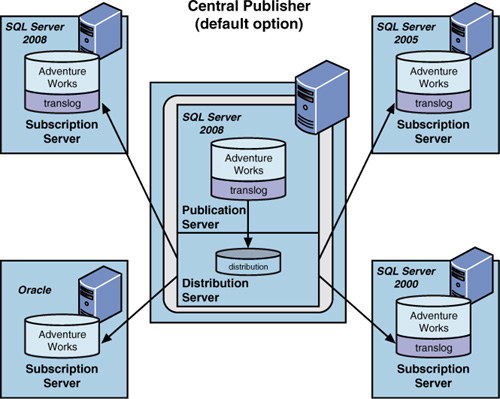
The Central Publisher Replication Model
The central publisher replication model, shown in Figure 1,
is Microsoft’s default scenario and a common model used if your primary
server has plenty of spare CPU cycles and you want a simple replication
model. In this scenario, one SQL Server performs the function of both
publisher and distributor. The publisher/distributor can have any number
of subscribers. These subscribers can come in many different varieties,
such as SQL Server 2008, SQL Server 2005, SQL Server 2000, SQL Server
7.0, and Oracle.
The central publisher scenario can be used in the following situations:
Creation of a copy of a database for ad hoc queries and report generation (classic use)
Publication of master lists to remote locations, such as master customer lists or master price lists
Maintenance
of a remote copy of an online transaction processing (OLTP) database
that could be used by the remote sites during communication outages
Maintenance of a spare copy of an OLTP database that could be used as a “hot spare” in case of server failure
However, it’s important to consider the following for this replication model:
If your OLTP server’s
activity is substantial and affects greater than 10% of your total data
per day, this scenario is not for you. Other scenarios or configurations
will better fit your needs.
If
your OLTP server is maximized on CPU, memory, and disk utilization, you
should also consider another data replication scenario because this one
is not for you either.
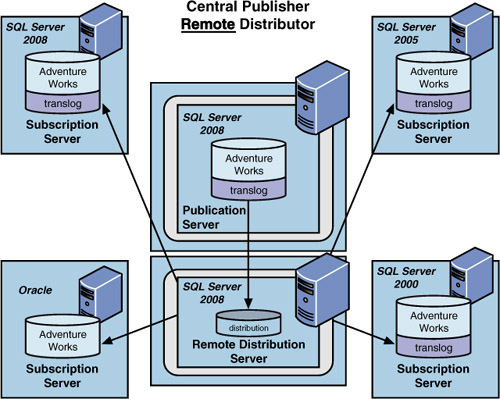
The Central Publisher with Remote Distributor Replication Model
The central publisher with remote distributor scenario, as shown in Figure 2,
is similar to the central publisher scenario and would be used in the
same general situations. The major difference between the two is that in
the central publisher with remote distributor scenario, a second server
is used to perform the role of distributor. This is highly desirable
when you need to free the publishing server from having to perform the
distribution task from a CPU, disk, and memory point of view. This is
also the best scenario from which to expand the number of publishers and
subscribers. Remember that a single distribution server can distribute
changes for several publishers. The publisher and distributor must be
connected to each other via a reliable, high-speed data link. This
remote distributor scenario is proving to be one of the best data
replication configurations due to its minimal impact on the publication
server and maximum distribution capability to any number of subscribers.
The
central publisher/remote distributor approach can be used for all the
same purposes as the central publisher scenario, and it also provides
the added benefit of having minimal resource impact on the publication
servers. If your OLTP server’s activity affects more than 10% of your
total data per day, this scenario can usually handle it without much
issue. If your OLTP server has overburdened CPU, memory, and disk
utilization, implementing this model easily solves these issues as well.
The central publisher/remote
distribution model is useful for the vast majority of all the data
replication configurations due to its optimal characteristics. Nine out
of ten replication scenarios that this author has implemented used the
remote distributor replication model.
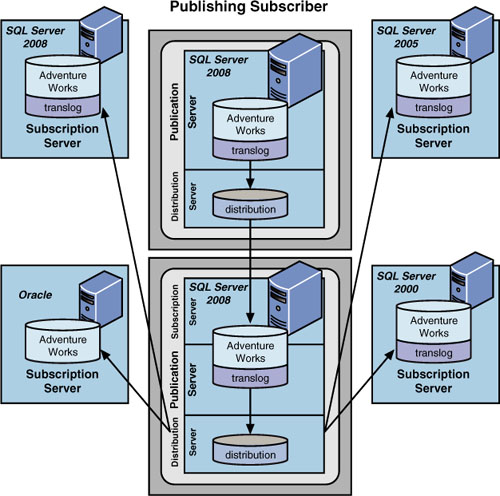
The Publishing Subscriber Replication Model
In the publishing subscriber scenario, as shown in Figure 3,
the publication server also has to act as a distribution server to one
subscriber. This subscriber, in turn, immediately publishes the data to
any number of other subscribers. The configuration depicted here does
not use a remote distribution configuration option but serves the same
distribution model purpose. This scenario is best used when a slow or
expensive network link exists between the original publishing server and
all the other potential subscribers. This allows the initial (critical)
publication of the data to be distributed from the original publishing
server to that single subscriber across the slow, unpredictable, or
expensive network line. Then, each of the many other subscribers can
subscribe to the data, using faster, more predictable, “local” network
lines than they would have with the publishing subscriber server.
A classic example of this
model is a company whose main office is in San Francisco and has several
branch offices in Europe. Instead of replicating changes to all the
branch offices in Europe, it replicates the updates to a single
publishing subscriber server in Paris. This publishing subscriber server
in Paris then replicates the updates to all other subscriber servers
around Europe.
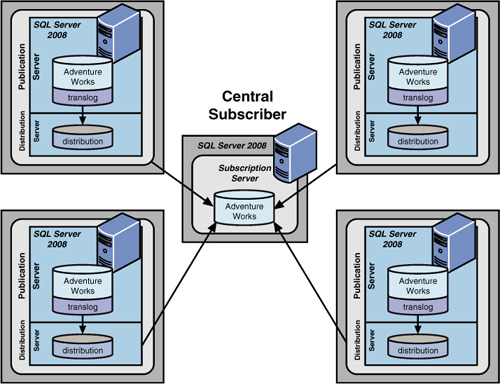
The Central Subscriber Replication Model
In the central subscriber scenario, as shown in Figure 4,
several publishers replicate data to a single, central subscriber.
Basically, this supports the concept of consolidating data at a central
site. An example of this might be consolidating all new orders from
regional sales offices to company headquarters. In such a situation, you
now have several publishers of the Orders
table, and you need to take some form of precaution, such as filtering
by region. This would guarantee that no one publisher could update
another region’s orders.
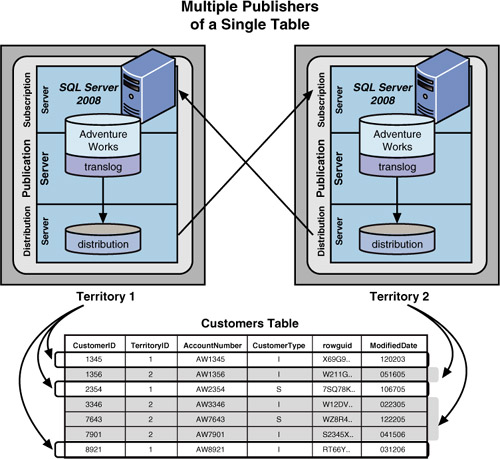
The Multiple Publishers with Multiple Subscribers Replication Model
In the multiple publishers with multiple subscribers scenario, as shown in Figure 5, a common table (such as the Customer
table) is maintained on every server participating in the scenario.
Each server publishes a particular set of rows (for example, the
customer rows in a customer’s own territory) that pertain to it—usually
via filtering on something that identifies that site to the data rows it
owns—and subscribes to the rows that all the other servers are
publishing. The result is that each server has all the data at all times
and can make changes to its data only. You must be careful when
implementing this scenario to ensure that all sites remain synchronized.
The most frequently used applications of this system are regional order
processing systems and reservation tracking systems. When setting up
this type of system, you need to make sure that only local users update
local data. This check can be implemented through the use of stored procedures, restrictive views, or a check constraint.
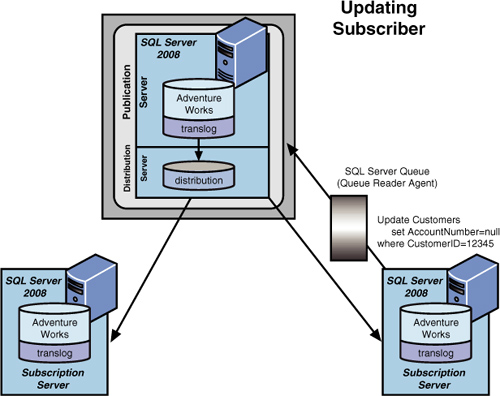
The Updating Subscribers Replication Model
SQL Server 2008 has
built-in functionality that allows the subscriber to update data in a
table to which it subscribes and have those updates automatically made
back to the publisher through either immediate or queued updates. This
model, called the updating subscribers model, utilizes a two-phase
commit process to update the publishing server as the changes are made
on the subscribing server. These updates are then replicated to any
other subscribers, but not to the subscriber that made the update.
Immediate updating
allows subscribers to update data only if the publisher will accept
these updates immediately. If the changes are accepted at the publisher,
they are propagated to the other subscribers. The subscribers must be
continuously and reliably connected to the publisher to make changes at
the subscriber.
Queued updating allows
subscribers to update data and then store those updates in a queue while
disconnected from the publisher. When the subscriber reconnects to the
publisher, the updates are propagated to the publisher. This
functionality utilizes SQL Server 2008 queues and the queue reader agent
or Microsoft Message Queuing (MSMQ).
A combination of
immediate updating with queued updating allows the subscriber to use
immediate updating but switch to queued updating if a connection cannot
be maintained between
the publisher and subscribers. After switching to queued updating,
reconnecting to the publisher, and emptying the queue, the subscriber
can switch back to immediate updating mode. An updating subscriber is
shown in Figure 6.
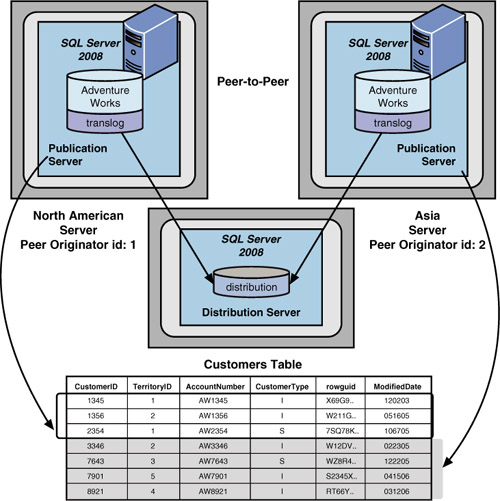
The Peer-to-Peer Replication Model
In SQL Server 2008, the
peer-to-peer replication model can provide a simpler way for all nodes
to have the same data and also gives them the capability to update this
data independently. Peer-to-peer replication is different from
subscriber updating in that there is no publisher/subscriber
hierarchical relationship. Each peer is equal in level. They establish
peer originator IDs so that each can keep track of where updates are
coming from and can be utilized if conflicts arise. Peers do not
subscribe to each other’s data; they share each other’s data. There are
several limitations with peer-to-peer replication, most of which are to
protect this peer-to-peer relationship from being corrupted or from
having major data conflicts arise. There are no queues or immediate
updating mechanisms involved, thus making this approach very useful when
you need to have the same data in more than one place and need to
update your local data to your heart’s content. If your peers typically
do not update the same rows (as in regional data peer-to-peers), this
replication model can be very reliable with minimal issues. This type of
replication model also allows for any number of peers and provides a
separate, very graphic wizard to configure each node in the topology.
Note
New peer nodes can also be
added to the topology without having to quiesce the topology, thus
increasing the availability of the entire replication model.
Figure 7
illustrates a typical peer-to-peer configuration with each peer using a
remote distribution server. Also note that with peer-to-peer
replication, you might decide to prohibit updates to the other nodes’
data by putting into place some type of stored procedure or view
restrictions that allow the local node to update only its own local
data. The example in Figure 7 shows that North American users can update customers with customer IDs between 1 and 3000, whereas Asian users can update customers with customer IDs between 3001 and 9000.